0. 引言
利用 Python 开发,借助 Dlib 库捕获摄像头中的人脸,进行实时人脸 68 个特征点标定;
支持多张人脸;
有截图功能;

图 1 工程效果示例( gif )
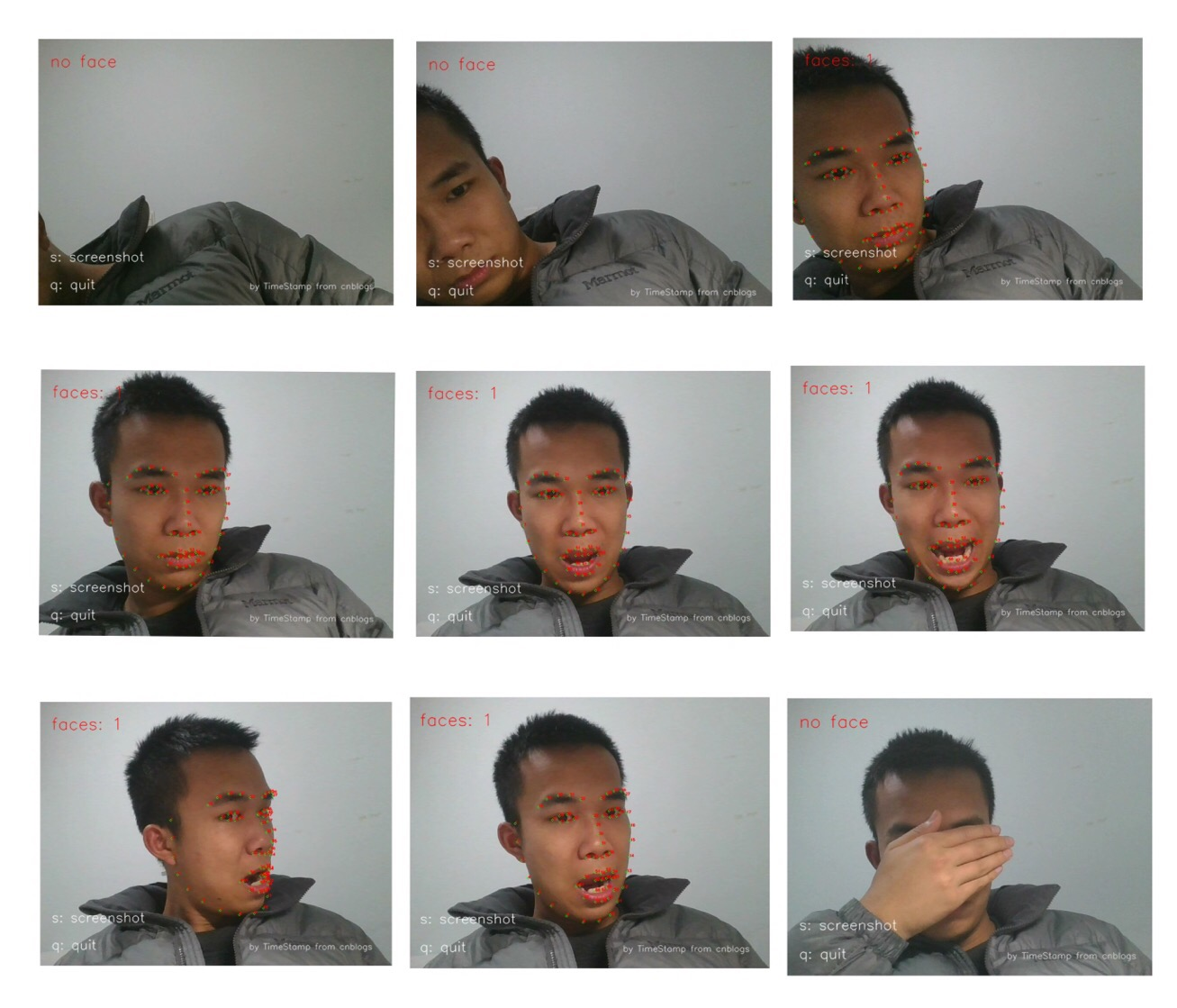
图 2 工程效果示例( 静态图片 )
1. 开发环境
Python: 3.6.3
Dlib: 19.7
OpenCv, NumPy
import dlib # 人脸检测的库 Dlib
import numpy as np # 数据处理的库 NumPy
import cv2 # 图像处理的库 OpenCv
2. 源码介绍
其实实现很简单,主要分为两个部分:摄像头调用 + 人脸特征点标定
2.1 摄像头调用
介绍下 OpenCv 中摄像头的调用方法,用到以下几个 OpenCv 函数:
cv2.VideoCapture(0) 创建一个对象;
cv2.VideoCapture.set(propId, value) 设置视频参数;
cv2.VideoCapture.isOpened() 检测读取视频是否成功;
cv2.VideoCapture.read() 返回是否读取成功和读取到的帧图像;
(具体可以参考官方文档:https://docs.opencv.org/2.4/modules/highgui/doc/reading_and_writing_images_and_video.html)
关于 cv2 中 VideoCapture 类的一些函数参数的说明如下:
# Sort by coneypo
# Updated at 10, Oct
# Blog: http://www.cnblogs.com/AdaminXie
###### 1. cv2.VideoCapture(), 创建cv2摄像头对象 / Open the default camera ######
"""
Python: cv2.VideoCapture() →
Python: cv2.VideoCapture(filename) →
filename – name of the opened video file (eg. video.avi) or image sequence (eg. img_%02d.jpg, which will read samples like img_00.jpg, img_01.jpg, img_02.jpg, ...)
Python: cv2.VideoCapture(device) →
device – id of the opened video capturing device (i.e. a camera index). If there is a single camera connected, just pass 0.
"""
cap = cv2.VideoCapture(0)
##### 2. cv2.VideoCapture.set(propId, value),设置视频参数; #####
"""
propId:
CV_CAP_PROP_POS_MSEC Current position of the video file in milliseconds.
CV_CAP_PROP_POS_FRAMES 0-based index of the frame to be decoded/captured next.
CV_CAP_PROP_POS_AVI_RATIO Relative position of the video file: 0 - start of the film, 1 - end of the film.
CV_CAP_PROP_FRAME_WIDTH Width of the frames in the video stream.
CV_CAP_PROP_FRAME_HEIGHT Height of the frames in the video stream.
CV_CAP_PROP_FPS Frame rate.
...
value: 设置的参数值/ Value of the property
"""
cap.set(3, 480)
##### 3. cv2.VideoCapture.isOpened(), 检查摄像头初始化是否成功, 返回true或false / check if open camera successfully #####
cap.isOpened()
##### 4. cv2.VideoCapture.read([imgage]) -> retval,image, 读取视频 / Grabs, decodes and returns the next video frame #####
"""
返回两个值:
一个是布尔值true/false,用来判断读取视频是否成功/是否到视频末尾
图像对象,图像的三维矩阵
"""
flag, im_rd = cap.read()
2.2 人脸特征点标定
shape_predictor_68_face_landmarks.dat 是 Dlib 训练好的模型,可以直接调用,进行人脸 68 个人脸特征点的标定;
我们需要进行的后续工作是,利用得到的特征坐标值进行特征点绘制;


图 3 Dlib 中人脸 68 个特征点位置说明
2.3 源码
既然已经能够利用训练好的模型进行特征点检测,需要进行的工作是将摄像头捕获到的视频流,转换为 OpenCv 的图像对象;
然后利用返回的特征点坐标值,绘制特征点,实时的再绘制到摄像头界面上,达到实时人脸检测追踪的目的;
利用 cv2.VideoCapture() 创建摄像头对象,然后利用 cv2.VideoCapture.read() 读取摄像头视频流中一帧帧图像;
然后就类似于单张图像进行人脸检测,对这单帧的图像利用 Dlib 进行特征点标定,然后绘制特征点;
按下 's' 键来获取当前截图,会存下带有时间戳的本地图像文件如 “screenshoot_1_2018-05-14-11-04-23.jpg”;
或者按下 'q' 键来退出摄像头窗口;
有四个 python 文件:
how_to_use_camera.py OpenCv 调用摄像头;
get_features_from_image.py 绘制 "data/face_to_detect/face_x.jpg" 本地图像人脸文件的特征点;
get_features_from_camera.py 从摄像头实时人脸检测绘制特征点;
remove_ss.py: 删除 "data/screenshots/" 路径下的所有截图;
( 源码都上传到了 GitHub: https://github.com/coneypo/Dlib_face_detection_from_camera )
这里只给出 get_features_from_camera.py 的源码;
get_features_from_camera.py:
# 调用摄像头,进行人脸捕获,和 68 个特征点的追踪
# Author: coneypo
# Blog: http://www.cnblogs.com/AdaminXie
# GitHub: https://github.com/coneypo/Dlib_face_detection_from_camera
# Created at 2018-02-26
# Updated at 2018-10-09
import dlib # 人脸识别的库 Dlib
import numpy as np # 数据处理的库 numpy
import cv2 # 图像处理的库 OpenCv
import time
# 储存截图的目录
path_screenshots = "data/screenshots/"
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('data/dlib/shape_predictor_68_face_landmarks.dat')
# 创建 cv2 摄像头对象
cap = cv2.VideoCapture(0)
# cap.set(propId, value)
# 设置视频参数,propId 设置的视频参数,value 设置的参数值
cap.set(3, 480)
# 截图 screenshots 的计数器
cnt = 0
# cap.isOpened() 返回 true/false 检查初始化是否成功
while cap.isOpened():
# cap.read()
# 返回两个值:
# 一个布尔值 true/false,用来判断读取视频是否成功/是否到视频末尾
# 图像对象,图像的三维矩阵
flag, im_rd = cap.read()
# 每帧数据延时 1ms,延时为 0 读取的是静态帧
k = cv2.waitKey(1)
# 取灰度
img_gray = cv2.cvtColor(im_rd, cv2.COLOR_RGB2GRAY)
# 人脸数
faces = detector(img_gray, 0)
# print(len(faces))
# 待会要写的字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 标 68 个点
if len(faces) != 0:
# 检测到人脸
for i in range(len(faces)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(im_rd, faces[i]).parts()])
for idx, point in enumerate(landmarks):
# 68 点的坐标
pos = (point[0, 0], point[0, 1])
# 利用 cv2.circle 给每个特征点画一个圈,共 68 个
cv2.circle(im_rd, pos, 2, color=(139, 0, 0))
# 利用 cv2.putText 输出 1-68
cv2.putText(im_rd, str(idx + 1), pos, font, 0.2, (187, 255, 255), 1, cv2.LINE_AA)
cv2.putText(im_rd, "faces: " + str(len(faces)), (20, 50), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
else:
# 没有检测到人脸
cv2.putText(im_rd, "no face", (20, 50), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 添加说明
im_rd = cv2.putText(im_rd, "press 'S': screenshot", (20, 400), font, 0.8, (255, 255, 255), 1, cv2.LINE_AA)
im_rd = cv2.putText(im_rd, "press 'Q': quit", (20, 450), font, 0.8, (255, 255, 255), 1, cv2.LINE_AA)
# 按下 's' 键保存
if k == ord('s'):
cnt += 1
print(path_screenshots + "screenshot" + "_" + str(cnt) + "_" + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + ".jpg")
cv2.imwrite(path_screenshots + "screenshot" + "_" + str(cnt) + "_" + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + ".jpg", im_rd)
# 按下 'q' 键退出
if k == ord('q'):
break
# 窗口显示
# 参数取 0 可以拖动缩放窗口,为 1 不可以
# cv2.namedWindow("camera", 0)
cv2.namedWindow("camera", 1)
cv2.imshow("camera", im_rd)
# 释放摄像头
cap.release()
# 删除建立的窗口
cv2.destroyAllWindows()
Mail : coneypo@foxmail.com